近日,阿里巴巴(Alibaba)旗下人工智能团队宣布开源其多模态大模型 Ming-Omni。 这一创新模型旨在实现对图像、文本、音频和视频等多种模态数据的统一处理和理解,代表着大模型在通向通用人工智能的道路上迈出了重要一步。
随着人工智能技术的飞速发展,大模型(Large Models)正逐渐从单一模态(如文本或图像)走向多模态,以期更好地理解和应对现实世界的复杂信息。 在这一趋势下,阿里巴巴(Alibaba)旗下的 InclusionAI 团队,近日带来了其重磅研究成果——开源多模态大模型 Ming-Omni。
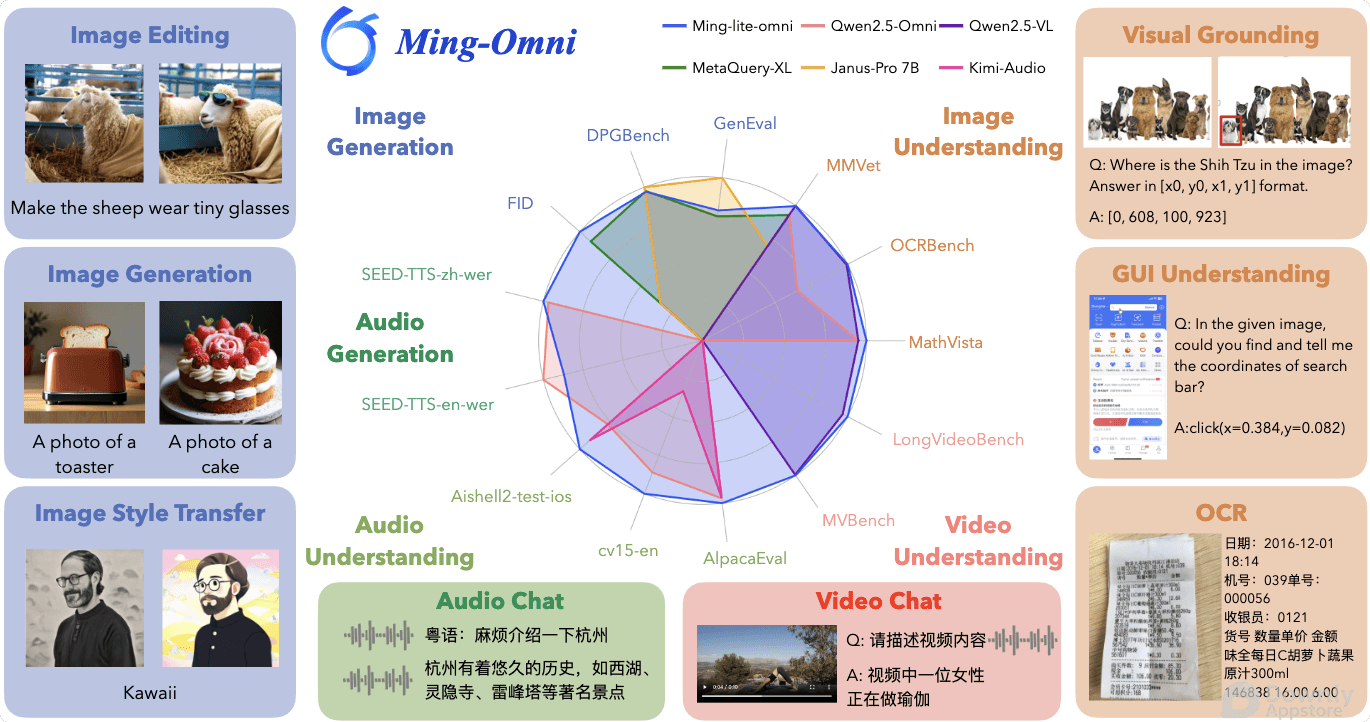 Ming-Omni 的发布,旨在打破不同数据模态之间的壁垒,实现对图像、文本、音频和视频等多种信息形式的统一处理、理解和生成。 这意味着,未来的 AI 系统将能够像人类一样,更全面、更立体地感知和交互世界。
Ming-Omni 的发布,旨在打破不同数据模态之间的壁垒,实现对图像、文本、音频和视频等多种信息形式的统一处理、理解和生成。 这意味着,未来的 AI 系统将能够像人类一样,更全面、更立体地感知和交互世界。
核心突破 全模态统一处理
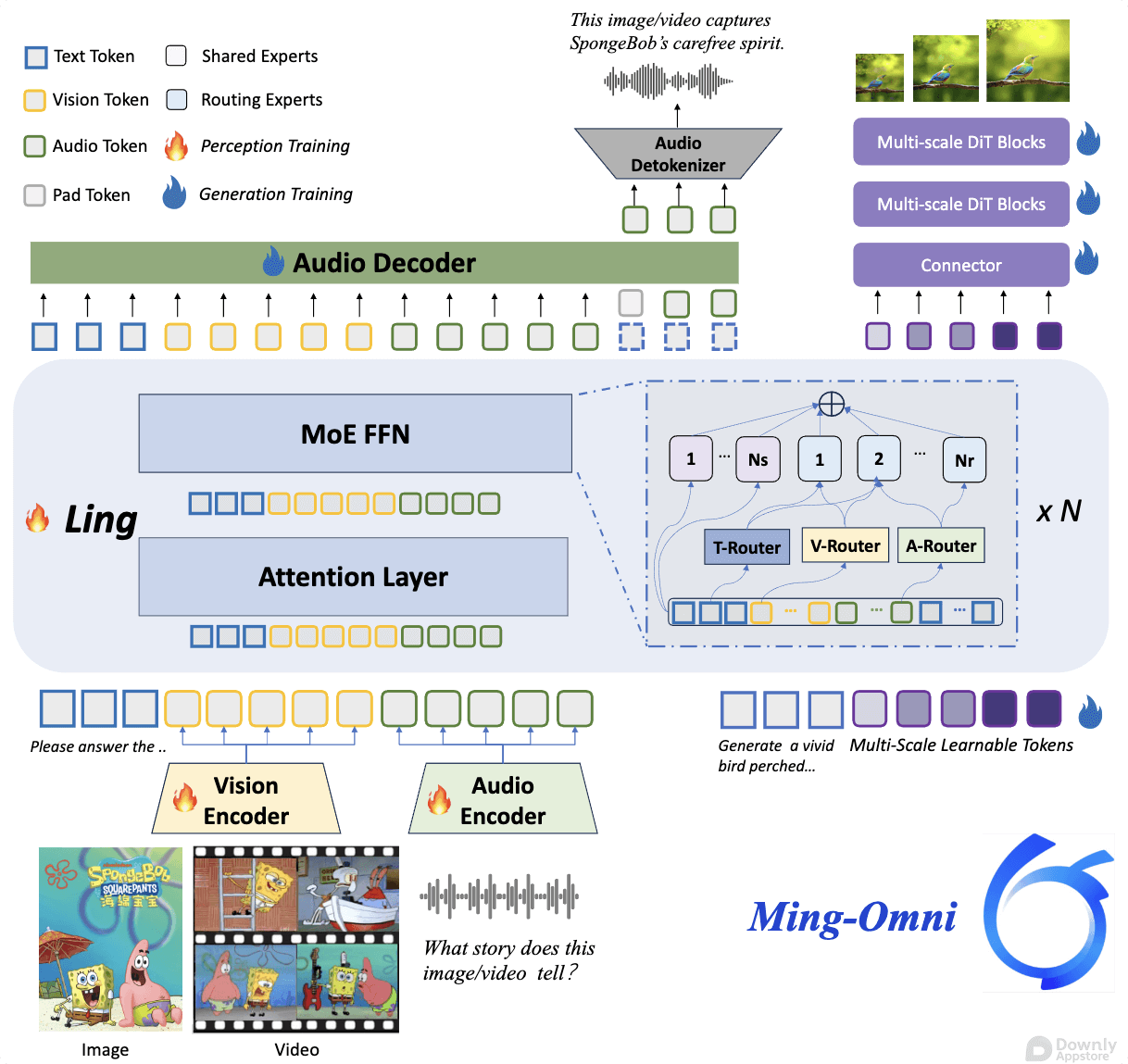
Ming-Omni 的核心亮点在于其卓越的全模态统一处理能力。 不同于以往需要为每种模态单独设计模型的做法,Ming-Omni 采用了一种更为通用的架构,能够同时理解和处理来自不同感官的信息。
1. 统一的表示与融合
Ming-Omni 创新性地将文本、图像、音频和视频数据编码为统一的特征表示,并通过先进的融合机制,将这些异构信息整合到一起。 这种统一的表示层使得模型能够捕捉不同模态之间复杂的关联和语义信息。
2. 跨模态理解与生成
得益于统一的架构,Ming-Omni 能够实现深度的跨模态理解。 例如,它可以根据一段视频和音频,生成相应的文字描述;或者根据一段文字,生成图像和语音。 这种能力为多种创新应用奠定了基础。
3. 大规模数据训练
为了达到如此强大的多模态处理能力,Ming-Omni 在海量的多模态数据集上进行了训练。 这些数据涵盖了文本、图像、音频和视频的广泛组合,使得模型能够学习到丰富的世界知识和跨模态的关联规律。
应用场景 无限可能
Ming-Omni 的多模态能力,使其在多个领域都展现出巨大的应用潜力
- 智能助理与对话系统 AI 助手将能更好地理解用户的语音指令、识别图片内容,并生成更丰富、更自然的回复,实现更接近人类的交互。
- 内容创作与编辑 辅助创作者生成多媒体内容,例如根据文本脚本生成视频草稿,或根据图像生成背景音乐。
- 多媒体搜索与推荐 用户可以通过图片、语音或视频片段进行搜索,并获得更精准的多模态搜索结果和推荐。
- 智能监控与分析 在安防、医疗等领域,模型可以同时分析视频画面、环境声音和文本信息,进行更全面的事件检测和预警。
- 教育与娱乐 提供更沉浸式、交互式的学习体验,或创造更丰富的游戏和虚拟世界内容。
开源赋能 推动生态发展
阿里巴巴此次开源 Ming-Omni,无疑将对整个 AI 社区产生深远影响。
- 加速研究与创新 为全球的学者和研究人员提供了强大的基座模型,降低了多模态 AI 研究的门槛,促进了更多创新性应用的涌现。
- 促进产业落地 开发者可以基于 Ming-Omni 构建定制化的多模态解决方案,加速 AI 技术在各行各业的落地应用。
- 构建开放生态 阿里巴巴通过开源,积极构建开放、协作的 AI 生态,与全球开发者共同推动人工智能的进步。
Ming-Omni 的发布,不仅仅是一个模型的开源,更是阿里巴巴在通向通用人工智能道路上迈出的坚实一步。 它为我们描绘了一个未来,AI 将能够以更全面的方式感知、理解和交互世界。




2025 AI 技术峰会

AI 实战课程
热门工具
AI 助手
智能对话,提升效率
智能图像处理
一键美化,智能修图
AI 翻译
多语言实时翻译



评论 (0)
暂无评论,快来发表第一条评论吧!