在人工智能领域,生成模型是研究的热点之一,它们能够学习数据的分布并生成新的样本,在图像、文本、音频等领域展现出巨大的潜力。流匹配模型(Flow Matching Models)作为一种新兴的生成模型技术,因其训练稳定性和样本生成效率而受到关注。然而,传统的流匹配模型训练方式通常是离线的。近日,一项名为 Flow-GRPO 的研究提出了一种将流匹配模型的训练与在线强化学习相结合的新方法,为提升生成模型的性能和灵活性开辟了新的道路。
流匹配模型:一种生成模型的新范式
流匹配模型是一种基于连续规范化流(Continuous Normalizing Flows)的生成模型。它通过学习一个将简单先验分布(例如,高斯分布)映射到复杂目标数据分布的连续变换(即“流”)来工作。与扩散模型类似,流匹配模型也涉及到一个时间维度的过程,但其核心思想是学习一个向量场,使得沿着该向量场演化的轨迹能够将先验分布推向目标分布。相比于早期的规范化流或扩散模型,流匹配模型在训练稳定性、样本生成速度以及处理高维数据方面展现出优势。
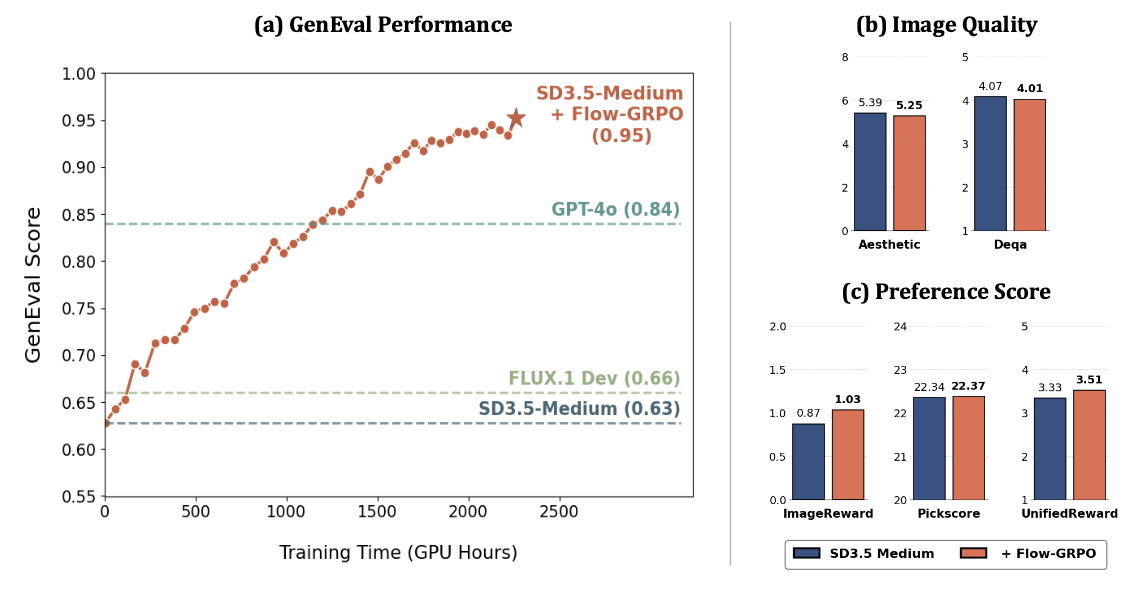
传统训练方法的局限
传统的流匹配模型训练通常采用离线的方式。这意味着模型在固定的数据集上进行训练,学习数据集的分布。一旦训练完成,模型就固定下来,无法根据新的数据或特定的目标进行实时调整。这限制了流匹配模型在一些需要动态适应或追求特定生成目标的场景中的应用。例如,在需要根据用户实时反馈调整生成内容的交互式应用中,离线训练的模型就显得不够灵活。
Flow-GRPO:引入在线强化学习
Flow-GRPO 技术的核心创新在于将流匹配模型的训练整合到在线强化学习(Online Reinforcement Learning)的框架中。强化学习是一种通过“试错”来学习最优决策的方法,智能体在环境中执行动作并接收奖励信号,根据奖励信号调整策略以最大化累积奖励。
在 Flow-GRPO 中,流匹配模型被视为一个生成策略,而训练过程则被转化为一个强化学习任务。模型生成的样本可以被视为“动作”,而一个“奖励函数”则根据生成样本的质量或与特定目标的符合程度来提供反馈。通过在线地与环境交互(例如,与用户进行交互,或在一个模拟环境中生成样本并评估其质量),流匹配模型可以根据实时获得的奖励信号不断调整其内部参数,优化生成策略。
Flow-GRPO 采用了一种基于梯度策略优化的方法(Gradient Policy Optimization),允许模型直接根据奖励信号的梯度来更新其生成策略,从而有效地将强化学习的在线适应能力与流匹配模型的生成能力结合起来。
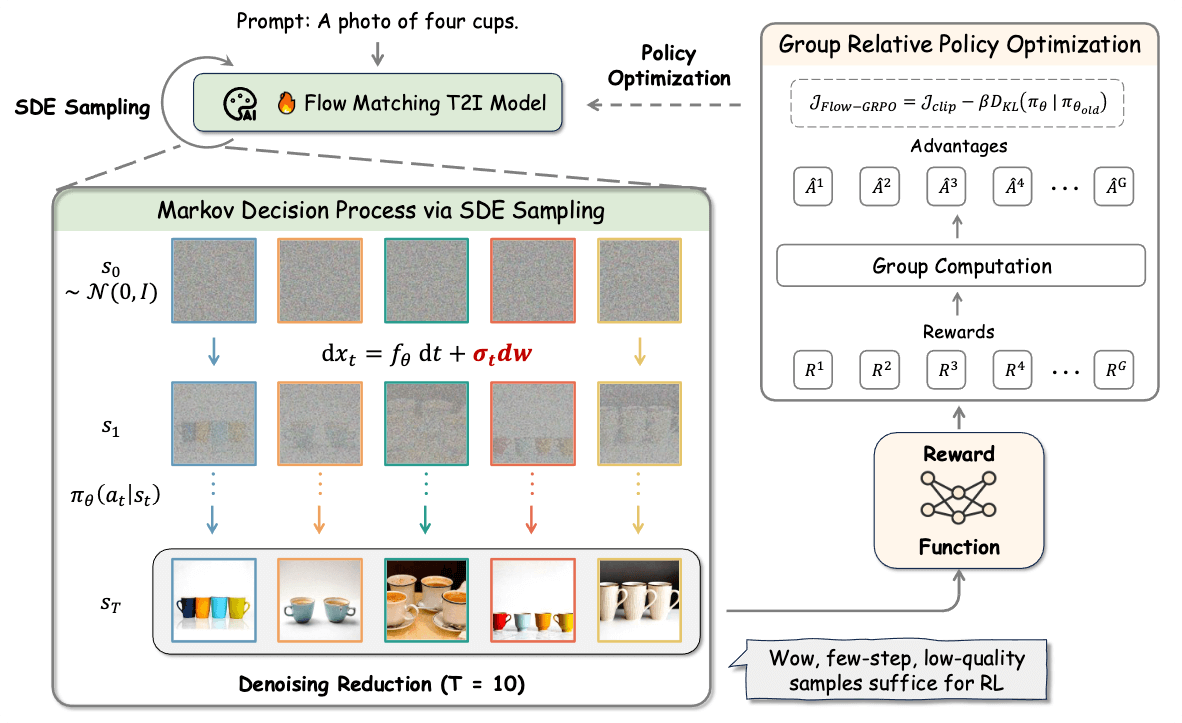
优势与应用前景
Flow-GRPO 方法带来了多重优势:
- 在线适应性: 模型可以根据实时数据和反馈进行调整,更好地适应动态变化的环境或满足个性化需求。
- 目标导向生成: 通过设计特定的奖励函数,可以引导模型生成符合特定目标或偏好的样本,例如生成具有特定属性的图像或满足特定风格的文本。
- 潜在的性能提升: 在线学习的过程有机会探索更广阔的策略空间,可能发现比离线训练更好的生成策略。
Flow-GRPO 技术为流匹配模型在更广泛的应用领域提供了可能性,例如:
- 交互式内容生成: 根据用户的实时输入和反馈,动态调整生成内容。
- 个性化推荐系统: 生成符合用户实时偏好的推荐内容。
- 机器人控制: 将流匹配模型用于学习复杂的连续控制策略。
- 科学计算与模拟: 在需要实时调整模型参数的场景中应用。

挑战与未来展望
将流匹配模型与在线强化学习结合也面临一些挑战,例如如何设计有效的奖励函数、如何处理强化学习训练中的样本效率问题以及如何保证在线学习过程的稳定性等。然而,Flow-GRPO 的提出为解决这些问题提供了一个有前景的框架。未来,研究人员将进一步探索更有效的在线训练算法,将 Flow-GRPO 应用于更复杂的生成任务,并研究其理论性质。这项工作为生成模型的在线学习和强化学习的应用开辟了新的研究方向。
相关推荐

2025 AI 技术峰会

AI 实战课程
热门工具
AI 助手
智能对话,提升效率
智能图像处理
一键美化,智能修图
AI 翻译
多语言实时翻译



评论 (0)
暂无评论,快来发表第一条评论吧!